3. روشهای گروه
 "دسته ای از درختان احمقانه که یاد می گیرند خطاهای یکدیگر را تصحیح کنند"
"دسته ای از درختان احمقانه که یاد می گیرند خطاهای یکدیگر را تصحیح کنند"
امروزه استفاده می شود برای:
همه چیز متناسب با الگوریتم کلاسیک (اما بهتر کار می کند)
سیستم های جستجو (★)
دید رایانه
تشخیص شی
الگوریتم های محبوب: جنگل تصادفی ، تقویت گرادیان
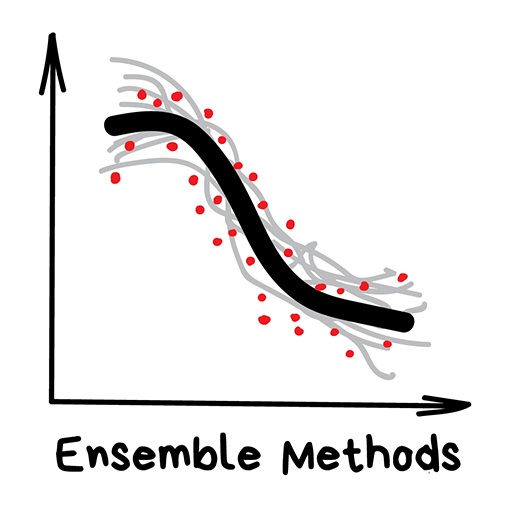
زمان آن رسیده است که روش های مدرن و بالغی انجام شود. گروه ها و شبکه های عصبی دو مبارز اصلی هستند که مسیر ما را به سمت یکتایی می کشانند. امروز آنها دقیق ترین نتایج را تولید می کنند و در تولید بسیار مورد استفاده قرار می گیرند.
با وجود همه اثربخشی ها ، ایده در پشت اینها بسیار ساده است. اگر مجموعه ای از الگوریتم های ناکارآمد را بدست آورید و آنها را مجبور به اصلاح اشتباهات یکدیگر کنید ، کیفیت کلی یک سیستم حتی از بهترین الگوریتم های فردی بالاتر خواهد بود.
در صورت گرفتن ناپایدارترین الگوریتم هایی که پیش بینی نتایج کاملاً متفاوت در مورد نویز کوچک در داده های ورودی هستند ، نتایج بهتری خواهید گرفت. مانند درختان رگرسیون و تصمیم گیری. این الگوریتم ها حتی به یک دور از دسترس در داده های ورودی نیز حساس هستند تا مدل ها دیوانه شوند.
در حقیقت ، این همان چیزی است که ما نیاز داریم.
درعوض ، سه روش آزمایش نبرد برای ایجاد مجموعه ها وجود دارد.
خروجی چندین مدل موازی به عنوان ورودی به آخرین مورد منتقل می شود که تصمیم نهایی را می گیرد.
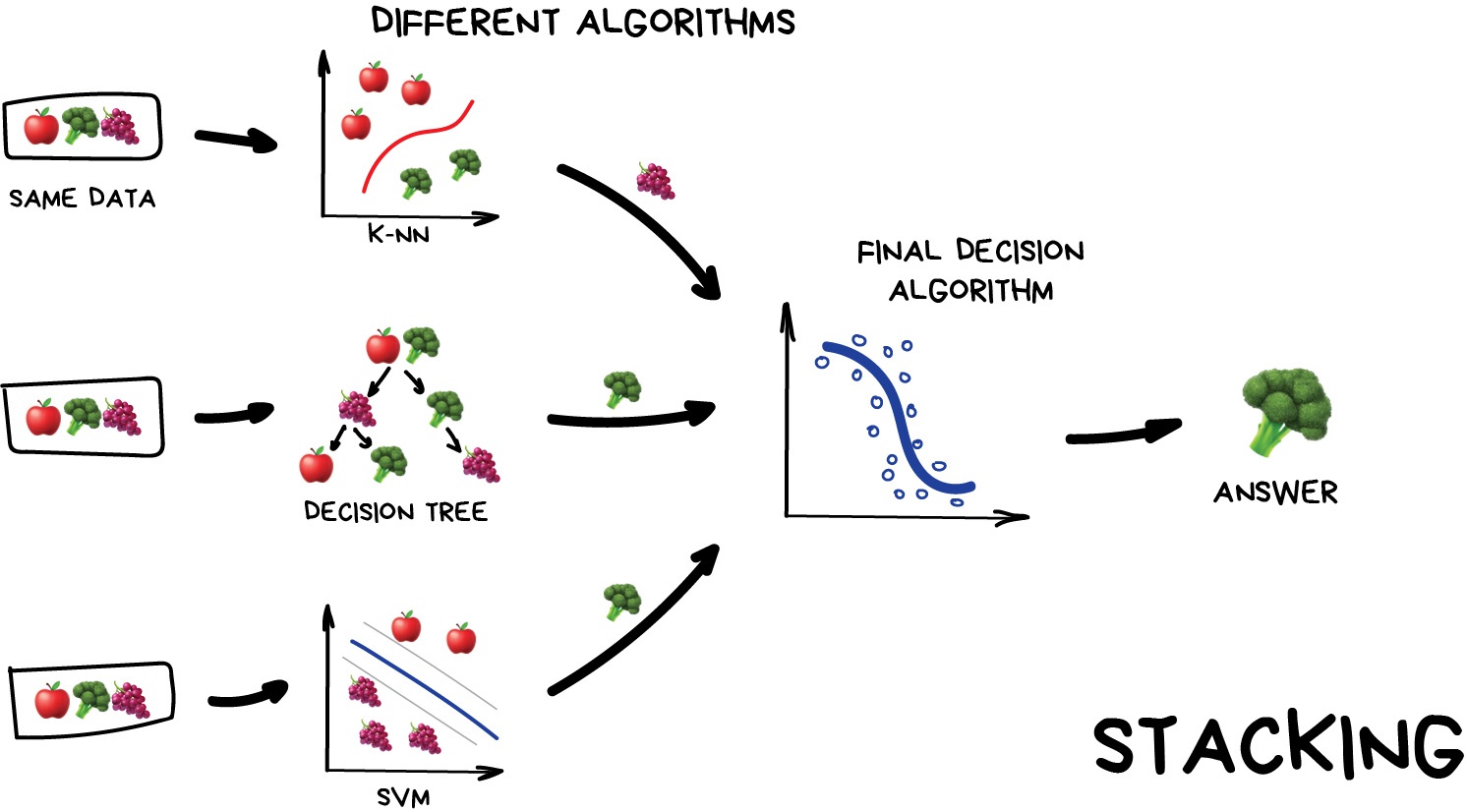 در اینجا تأکید بر کلمه "متفاوت" است. مخلوط کردن الگوریتم های مشابه روی همان داده ها معنی ندارد. انتخاب الگوریتم ها کاملاً به عهده شماست. با این حال ، برای مدل تصمیم گیری نهایی ، رگرسیون معمولاً انتخاب خوبی است.
در اینجا تأکید بر کلمه "متفاوت" است. مخلوط کردن الگوریتم های مشابه روی همان داده ها معنی ندارد. انتخاب الگوریتم ها کاملاً به عهده شماست. با این حال ، برای مدل تصمیم گیری نهایی ، رگرسیون معمولاً انتخاب خوبی است.
داده ها در زیرمجموعه های تصادفی ممکن است تکرار شود. به عنوان مثال ، از مجموعه ای مانند "1-2-3" می توانیم زیر مجموعه هایی مانند "2-2-3" ، "1-2-2" ، "3-1-2" و غیره را بدست آوریم. ما از این مجموعه داده های جدید برای آموزش چندین بار با همان الگوریتم استفاده می کنیم و سپس پاسخ نهایی را از طریق رأی اکثریت ساده پیش بینی می کنیم.
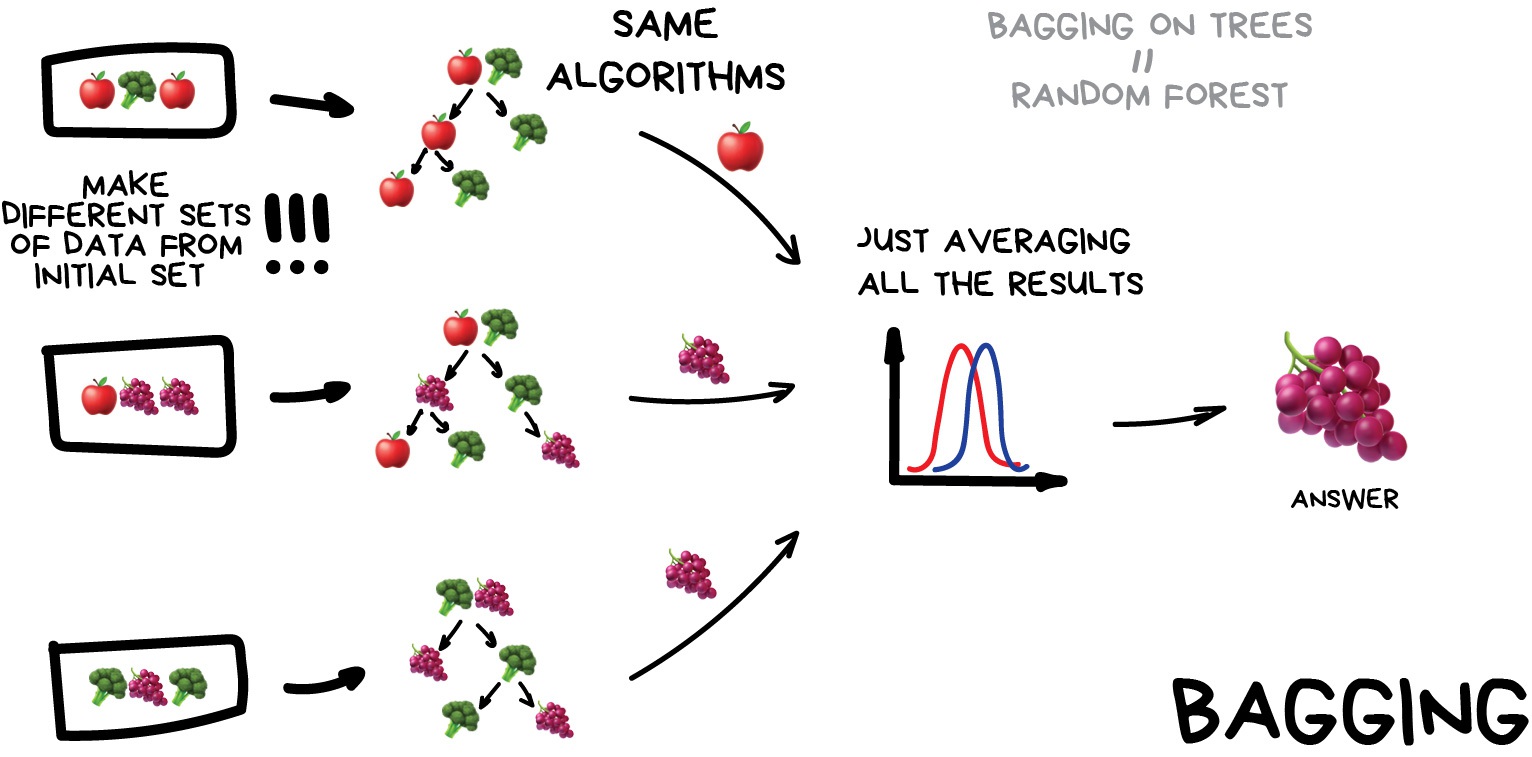 مشهورترین نمونه کیسه زدن ، الگوریتم Random Forest است که به سادگی حمل کردن درختان تصمیم گیری (که در بالا نشان داده شده است) است. هنگامی که برنامه دوربین گوشی خود را باز می کنید و می بینید که جعبه هایی در اطراف چهره افراد قرار دارد - این احتمالاً نتیجه کار Random Forest است. شبکه های عصبی برای اجرای زمان واقعی بسیار کند هستند اما طبقه بندی ایده آل است زیرا می تواند درختان را بر روی همه سایه بانهای یک کارت تصویری یا پردازنده های جدید ML محاسبه کند.
مشهورترین نمونه کیسه زدن ، الگوریتم Random Forest است که به سادگی حمل کردن درختان تصمیم گیری (که در بالا نشان داده شده است) است. هنگامی که برنامه دوربین گوشی خود را باز می کنید و می بینید که جعبه هایی در اطراف چهره افراد قرار دارد - این احتمالاً نتیجه کار Random Forest است. شبکه های عصبی برای اجرای زمان واقعی بسیار کند هستند اما طبقه بندی ایده آل است زیرا می تواند درختان را بر روی همه سایه بانهای یک کارت تصویری یا پردازنده های جدید ML محاسبه کند.
در بعضی از کارها ، توانایی اجرای جنگل تصادفی به طور موازی از ضرر کوچک در دقت نسبت به تقویت بیشتر است. به خصوص در پردازش در زمان واقعی. همیشه یک معامله وجود دارد.
 الگوریتم های تقویت کننده یک به یک به طور متوالی آموزش داده می شوند. هر مورد بعدی بیشترین توجه خود را به نقاط داده ای که توسط مورد قبلی اشتباه گرفته شده است ، می پردازد.
الگوریتم های تقویت کننده یک به یک به طور متوالی آموزش داده می شوند. هر مورد بعدی بیشترین توجه خود را به نقاط داده ای که توسط مورد قبلی اشتباه گرفته شده است ، می پردازد.
همانند ذهن ، ما از زیر مجموعه داده های خود استفاده می کنیم اما این بار آنها به طور تصادفی تولید نمی شوند. در حال حاضر ، در هر نمونه بخشی از داده ها را می گیریم که الگوریتم قبلی پردازش نشده است. بنابراین ، ما یک الگوریتم جدید را یاد می گیریم که خطاهای قبلی را برطرف کند.
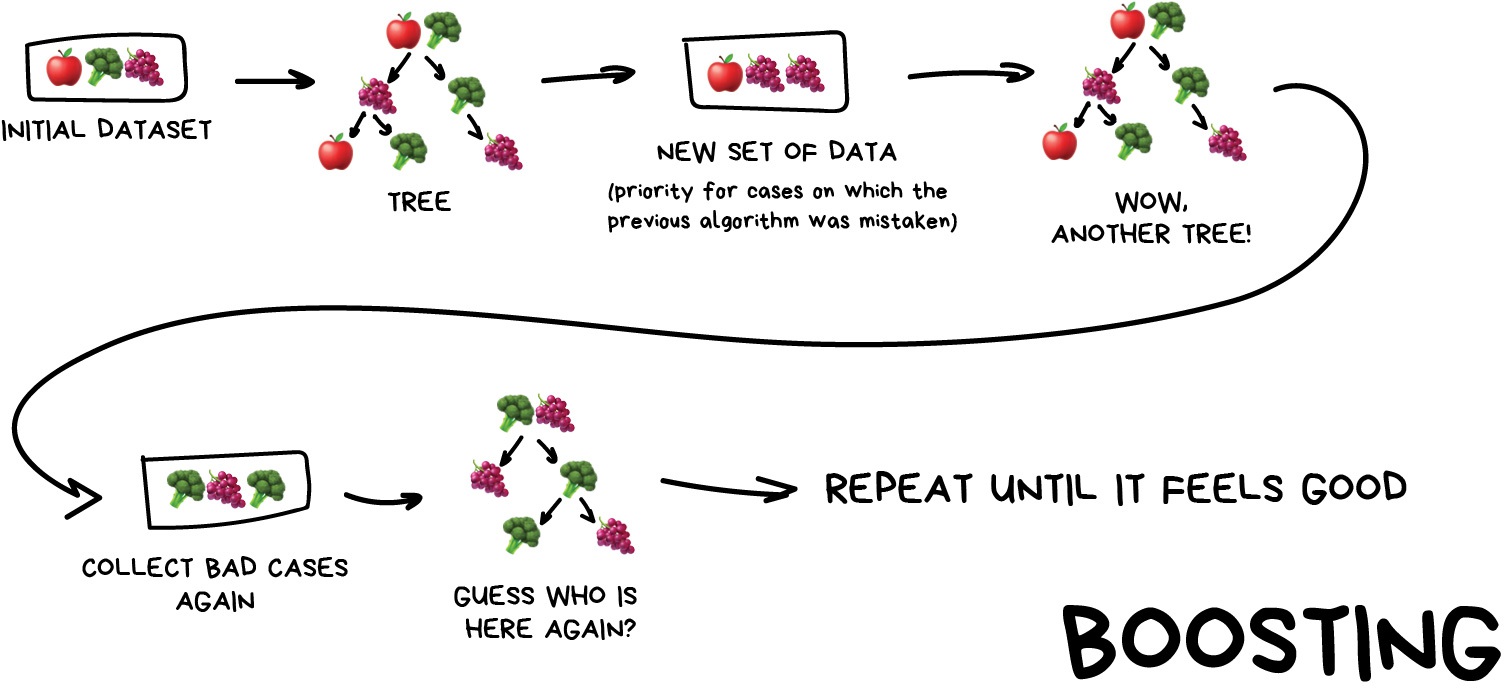 مزیت اصلی در اینجا - بسیار بالا ، حتی غیرقانونی در بعضی از کشورها از طبقه بندی دقیق که همه بچه های خونسرد می توانند به آنها حسادت کنند. منفی از قبل بیرون زده شده بود - این موازی نیست. اما هنوز سریعتر از شبکه های عصبی است. این مانند مسابقه بین کامیون کمپرسی و پیست مسابقه است. کامیون می تواند کارهای بیشتری انجام دهد ، اما اگر می خواهید سریع بروید - یک ماشین بگیرید.
مزیت اصلی در اینجا - بسیار بالا ، حتی غیرقانونی در بعضی از کشورها از طبقه بندی دقیق که همه بچه های خونسرد می توانند به آنها حسادت کنند. منفی از قبل بیرون زده شده بود - این موازی نیست. اما هنوز سریعتر از شبکه های عصبی است. این مانند مسابقه بین کامیون کمپرسی و پیست مسابقه است. کامیون می تواند کارهای بیشتری انجام دهد ، اما اگر می خواهید سریع بروید - یک ماشین بگیرید.
اگر می خواهید یک مثال واقعی از تقویت باشید - Facebook یا Google را باز کنید و در جستجو تایپ کنید. آیا می توانید صدای ارتشی از درختان را بشنوید که در حال غرق شدن و سر و صدا کردن یکدیگر هستند تا نتایج را با توجه به مرتب سازی مرتب کنند دلیل این است که آنها از تقویت استفاده می کنند.
قسمت دهم



